
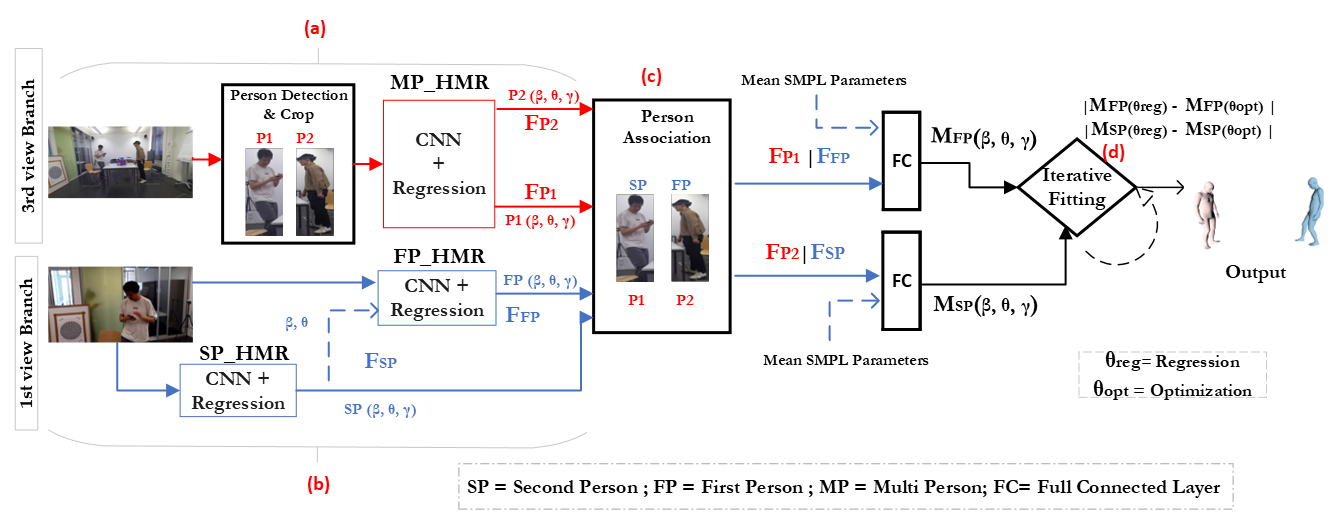

✨ This paper addresses the problem of estimating the 3D pose and shape of two interacting people from videos captured by a wearable face-fronting camera worn by one of them. In the first-view, the wearer is hidden behind the camera while the interactee is typically only partly visible due to the relative closeness between interacting people, hence presenting a challenge for their accurate 3D pose and shape estimation. Our main insight is to take advantage of the third-view perspective, available at training time, to learn a mapping between the interactee, as visible from the first-view, and the first-person, as visible from third-view. To this goal, we propose a two streams architecture whose branches during training take as input the first-view and the third-view respectively and extract both image features and temporary SMPL parameters separately from both views for the two interacting persons, to match the interactee in both views. These features are subsequently used to estimate 3D pose and shape parameters through iterative fitting and optimization.